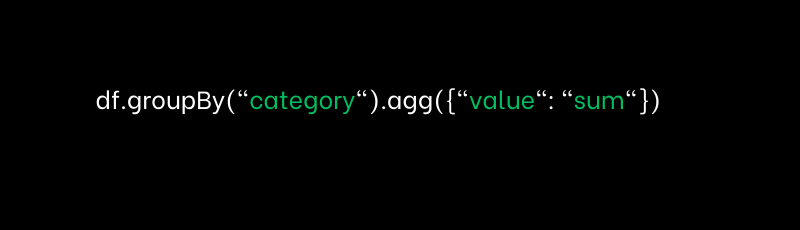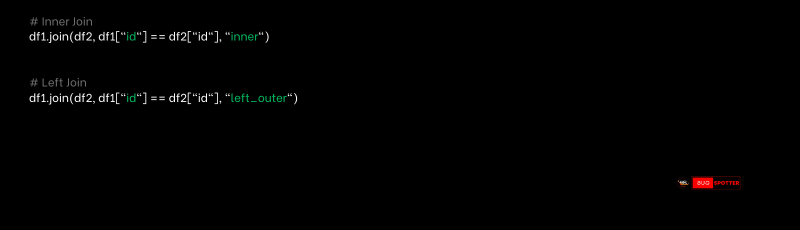1.What is Apache Spark and how does PySpark relate to it?
Apache Sparkis an open-source, distributed computing system designed for fast processing of large datasets. It provides an interface for programming entire clusters with implicit data parallelism and fault tolerance.
PySpark is the Python API for Apache Spark, which allows Python developers to use the power of Spark in their applications. It provides a high-level API for data processing, machine learning, and streaming, enabling Python developers to interact with Spark without having to learn Scala or Java.
2.What is the difference between RDD (Resilient Distributed Dataset) and DataFrame in PySpark?
RDD: The core abstraction in Spark, an RDD is a distributed collection of objects. RDDs are fault-tolerant and distributed, allowing for parallel processing, but they don’t provide optimizations like DataFrames do.
DataFrame: A higher-level abstraction built on top of RDDs. It represents a distributed collection of data organized into named columns (like a table in a database). DataFrames are optimized by Spark’s Catalyst query optimizer and Tungsten execution engine.
3.What are the key features of PySpark?
Distributed computing for large-scale data processing.
High-level APIs for data manipulation (DataFrame and SQL).
Fault tolerance via RDDs.
In-memory computing for speed.
Supports machine learning via PySpark MLlib.
Integration with other big data tools like Hadoop and Hive.
4.How do you create a DataFrame in PySpark?
You can create a DataFrame in PySpark in several ways:
5.What is a SparkSession in PySpark and why is it important?
SparkSession is the entry point to PySpark functionality. It is responsible for creating DataFrames, executing SQL queries, and managing configurations. It replaces SQLContext and HiveContext in earlier versions of Spark.
It simplifies working with Spark, and you can perform SQL queries and manage Spark configurations through this session.
6.Explain the difference between a “wide” and a “narrow” transformation in Spark.
Narrow Transformation: The data required for the transformation is present in the same partition (e.g., map(), filter()). No shuffling of data is required.
Wide Transformation: Data needs to be shuffled across partitions (e.g., groupBy(), join()). These operations involve a lot of data movement between nodes in the cluster.
7.How can you read a CSV file using PySpark?
This command reads a CSV file into a DataFrame, where header=True treats the first row as column names, and inferSchema=True automatically determines data types.
8.What are the common functions available in PySpark DataFrame API?
select(): Select columns from a DataFrame.
filter()/where(): Filter rows based on conditions.
groupBy(): Group the data based on column(s).
agg(): Aggregate data (e.g., sum, count, etc.).
join(): Join DataFrames.
show(): Display data.
withColumn(): Add or modify a column.
9.What is the difference between select() and selectExpr() in PySpark?
select(): Used for selecting columns directly by name or by applying functions to columns.
selectExpr(): Allows using SQL expressions to select and manipulate columns, providing more flexibility with complex expressions.
10.Explain the concept of groupBy() and agg() in PySpark DataFrame.
groupBy(): Groups the DataFrame by one or more columns.
11.What is the use of filter() and where() in PySpark DataFrames?
Both filter() and where() are used for filtering rows based on conditions. The difference is mostly syntactic:
filter(): Used for filtering based on conditions.
where(): Equivalent to filter(), but is SQL-like and often used in Spark SQL queries.
12.What is a UDF (User Defined Function) in PySpark? When would you use it?
A UDF is a user-defined function that extends the functionality of PySpark. It allows you to write custom functions for column-level operations in a DataFrame when built-in functions are not sufficient. Example:
13.How do you perform joins in PySpark?
14.What is the difference between join() and left_outer_join()?
join(): By default, it performs an inner join, returning rows where there is a match in both DataFrames.
left_outer_join(): It performs a left outer join, returning all rows from the left DataFrame and matched rows from the right DataFrame. If there is no match, NULL values are returned for columns from the right DataFrame.
15.What are some common performance optimization techniques in PySpark?
Use DataFrame API over RDDs for better optimization.
Partition data based on the size of the dataset.
Use repartition() to optimize for parallelism.
Cache or persist intermediate results to avoid recomputing them.
Avoid using shuffles as much as possible, as they are expensive.
Use broadcast joins for small lookup tables.
16.Explain the concept of partitioning in PySpark. How does partitioning impact performance?
Partitioning determines how data is distributed across the cluster. Proper partitioning can reduce shuffling, which enhances performance. For example, if a dataset is partitioned by a column used in a join() operation, Spark will perform the join more efficiently.
17.What is the significance of repartition() and coalesce()?
repartition(): Increases or decreases the number of partitions, which involves reshuffling the data across the cluster.
coalesce(): Reduces the number of partitions without reshuffling the data, making it more efficient when you need to decrease the number of partitions (e.g., for output).
18.What is the role of cache() and persist() in PySpark?
cache(): Stores data in memory for faster access in subsequent actions.
persist(): Allows you to store data in different storage levels (memory, disk, etc.).
19.How can you improve the performance of PySpark jobs when working with large datasets?
Use broadcast joins when joining large datasets with small ones.
Avoid shuffling by partitioning data appropriately.
Cache intermediate results if they are reused.
Tune Spark’s configuration settings (e.g., memory and CPU resources).
20.What is a shuffle operation in Spark, and how does it impact performance?
A shuffle operation involves redistributing data across different partitions, which is an expensive process. It can occur during operations like groupBy(), join(), or sorting.
21. What is the role of the Catalyst optimizer in Spark?
The Catalyst optimizer in Spark optimizes query execution plans for Spark SQL, DataFrames, and Datasets. It improves performance by:
Logical Plan Optimization: Simplifies queries (e.g., predicate pushdown, projection pruning).
Physical Plan Generation: Generates efficient execution plans based on cost.
Cost-Based Optimization (CBO): Chooses the best execution plan considering data and resource factors.
Query Rewrites: Transforms queries into more efficient forms.
Support for UDFs: Allows custom functions with optimization.
22. How does Spark handle fault tolerance in distributed computing?
Spark ensures fault tolerance through:
RDD Lineage: Tracks the sequence of transformations; lost data can be recomputed using lineage.
Data Replication: For DataFrames and Datasets, data may be replicated across nodes using distributed storage (e.g., HDFS).
Checkpointing: Saves RDDs to stable storage (e.g., HDFS) to recover data after failures.
Difference Between Spark and Hadoop MapReduce
23.Differences Between Apache Spark and Hadoop MapReduce
1. Performance
Apache Spark is faster than Hadoop MapReduce due to its in-memory processing, which avoids the need for disk I/O between each job phase. In contrast, MapReduce stores intermediate data on disk, resulting in slower execution.
2. Ease of Use
Apache Spark provides high-level APIs in multiple programming languages (Python, Java, Scala, R), making it easier for developers to work with. On the other hand, Hadoop MapReduce generally requires writing more complex Java code.
3. Data Processing Model
Apache Spark processes data in-memory, significantly reducing the time required for transformations and actions. In contrast, Hadoop MapReduce performs disk-based processing, where data is read and written to disk after every map and reduce operation.
4. Fault Tolerance
Apache Spark uses RDD lineage to recompute lost data after a failure. This approach eliminates the need for replication. On the other hand, Hadoop MapReduce relies on data replication in HDFS for fault tolerance, ensuring multiple copies of data are available in case of failure.
5. Real-time Processing
Apache Spark supports real-time stream processing through Spark Streaming. Hadoop MapReduce is limited to batch processing and does not support real-time data handling.
24.What is Spark’s in-memory computation model and how does it enhance performance?
Spark’s in-memory computation model means it stores intermediate data in memory (RAM) instead of writing it to disk after each operation. This reduces I/O overhead and speeds up processing. By keeping data in-memory across operations, Spark can perform iterative algorithms and complex queries much faster compared to Hadoop MapReduce, which writes intermediate results to disk after each map and reduce phase.
25. What is the role of the Tungsten execution engine in Spark?
The Tungsten execution engine optimizes Spark’s execution by improving memory management, code generation, and query optimization. It boosts performance through:
Memory management: Efficient use of off-heap memory (bypassing JVM garbage collection).
Code generation: Compiles bytecode dynamically for better CPU efficiency.
Optimized data processing: Reduces overhead for tasks like sorting and aggregation.
26. How does Spark handle data shuffling and why is it expensive?
Data shuffling in Spark occurs when data is exchanged between nodes (e.g., during operations like groupBy(), join(), or reduceByKey()). It involves moving data across partitions and often across machines, which requires sorting, network transfer, and disk I/O.
Shuffling is expensive because:
It involves disk and network I/O, which are slower than in-memory operations.
It triggers sorting and data movement, leading to significant overhead in both time and resources.