End to End Data Pipeline with AWS
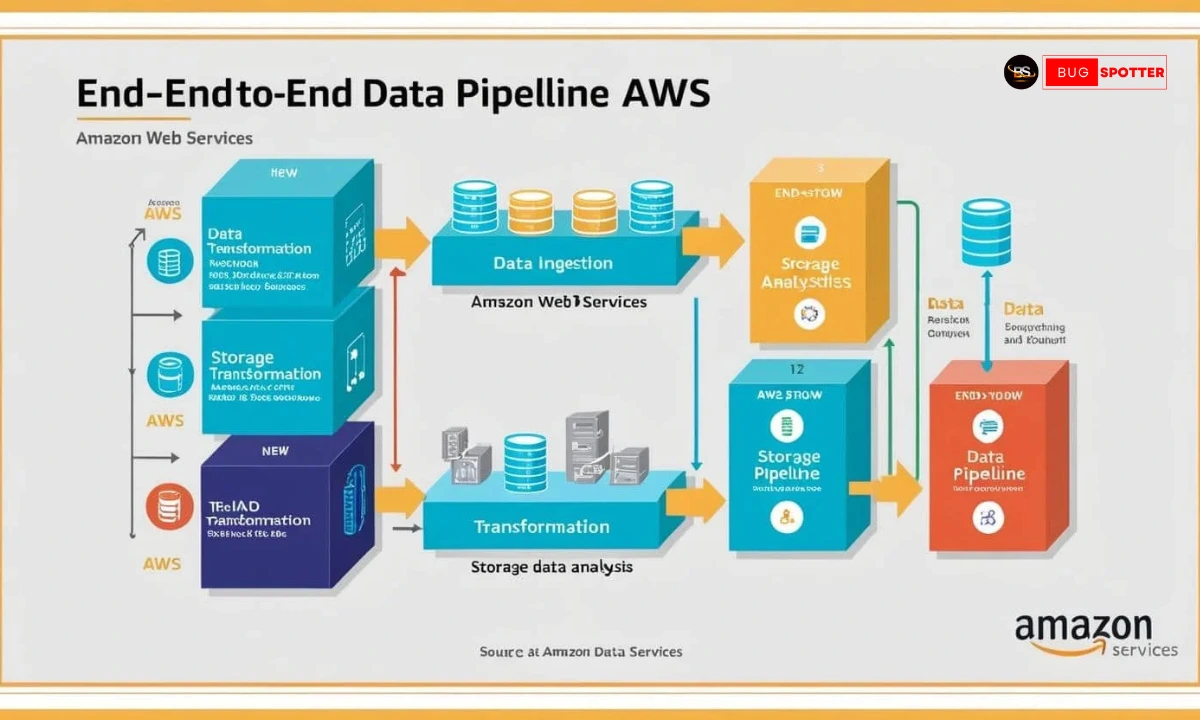
End to End Data Pipeline with AWS
What is a Data Pipeline?
A data pipeline is a series of automated processes and tools that collect, clean, transform, store, and analyze data in a way that ensures timely delivery and reliability. The purpose of a data pipeline is to streamline workflows and reduce the manual effort of handling large volumes of data across systems.
Key AWS Services for Data Pipeline Development
AWS offers several key services to help with building a data pipeline. Here’s a breakdown of each service:
1. Amazon S3 (Simple Storage Service)
- Role: Data storage (raw and processed).
- Why Use It: S3 is a scalable, durable, and cost-effective storage solution. It provides high availability and security features for data storage. You can use S3 to store raw data before processing and also store transformed datasets for further analysis.
- Use Cases: Storing log files, backup data, images, and unstructured data.
2. AWS Lambda
- Role: Serverless compute for data processing.
- Why Use It: AWS Lambda allows you to run code without provisioning or managing servers. It can trigger data transformation or processing tasks in response to events like new data uploads to S3.
- Use Cases: Real-time data transformation (e.g., converting formats, aggregating data).
3. Amazon Kinesis
- Role: Real-time data streaming.
- Why Use It: Kinesis handles real-time streaming data, providing the ability to collect and process data from hundreds of thousands of sources (e.g., IoT devices, website activity).
- Use Cases: Real-time analytics, live event data processing, and monitoring.
4. AWS Glue
- Role: Managed ETL (Extract, Transform, Load) service.
- Why Use It: Glue automates the process of data discovery, transformation, and loading into data warehouses. It supports a serverless environment for handling your ETL jobs.
- Use Cases: Data transformation, cleansing, and preparation for analytics.
5. Amazon Redshift
- Role: Data warehousing.
- Why Use It: Redshift is a fully managed data warehouse service that allows you to store large volumes of structured data and perform complex queries at high speed.
- Use Cases: Analytical queries on large datasets, data aggregation, and business intelligence reporting.
6. Amazon RDS (Relational Database Service)
- Role: Relational database for structured data.
- Why Use It: AWS RDS is used for storing structured data in databases like MySQL, PostgreSQL, and Oracle. You can automate backups, patching, and scaling of your databases.
- Use Cases: Storing transactional data, customer records, and operational data.
7. Amazon DynamoDB
- Role: NoSQL database for fast, scalable data storage.
- Why Use It: DynamoDB offers key-value and document database models, allowing you to store and retrieve any amount of data with high availability and low latency.
- Use Cases: Real-time analytics, user session storage, and high-performance applications.
8. Amazon QuickSight
- Role: Business Intelligence (BI) and data visualization.
- Why Use It: QuickSight is a fast, cloud-powered business intelligence tool that enables you to visualize data, create dashboards, and generate insights.
- Use Cases: Creating interactive reports, dashboards, and data visualizations for business stakeholders.
Step-by-Step Guide: Building an End-to-End Data Pipeline with AWS
Step 1: Data Ingestion
Collecting Data:
- Raw data can come from multiple sources, such as web logs, social media feeds, IoT devices, or databases.
- You can use Amazon Kinesis to ingest real-time streaming data or AWS S3 for batch uploads of large datasets.
Storage Solutions:
- Once ingested, data is stored temporarily in S3 buckets (raw data) before it undergoes further transformation or analysis.
Step 2: Data Transformation & Processing
Data Processing using AWS Lambda:
- AWS Lambda can be triggered to automatically process incoming data. For example, you can trigger a Lambda function every time new data is uploaded to S3.
- Lambda can clean, format, aggregate, or perform calculations on data before sending it to a final storage solution.
ETL with AWS Glue:
- Use AWS Glue for more complex ETL jobs. Glue crawls data sources and automatically discovers metadata.
- Glue then transforms the data and loads it into data stores like Amazon Redshift or S3.
Step 3: Data Storage
- Storing Raw or Transformed Data:
- Store processed data in Amazon S3 or directly in Amazon Redshift for analytical purposes.
- You may also use Amazon RDS or DynamoDB to store structured data for applications or reporting purposes.
Step 4: Data Analytics & Visualization
Performing Analytics with Redshift:
- After data is stored in Redshift, you can run complex SQL queries to analyze the data and generate insights.
- Amazon QuickSight can be integrated with Redshift to create interactive dashboards, charts, and visualizations.
Real-Time Analytics:
- If you’re processing real-time data via Kinesis, the data can be analyzed instantly using Kinesis Data Analytics.
Step 5: Automation & Orchestration
- AWS Step Functions for Orchestration:
- AWS Step Functions can automate and orchestrate the flow of data through the pipeline. For instance, after data is ingested into Kinesis, it can trigger Lambda functions, which then push the processed data to S3 or Redshift.
- Step Functions allow you to create workflows and ensure that all tasks are executed in sequence with error handling.
Best Practices for Building an Efficient Data Pipeline with AWS
Scalability:
- Ensure your pipeline is designed for scalability to handle growing volumes of data. Leverage AWS services like Kinesis and Redshift to scale horizontally.
Data Quality:
- Implement data validation and cleaning at each stage using AWS Lambda or Glue to ensure data integrity.
Error Handling:
- Set up error monitoring and automatic retries for failed jobs using AWS Step Functions or CloudWatch to keep the pipeline running smoothly.
Security:
- Implement security best practices such as encryption at rest (e.g., with KMS), IAM roles, and Access Control to safeguard sensitive data.
Cost Optimization:
- Use AWS pricing calculators to estimate costs and optimize the pipeline by selecting appropriate instance types, storage solutions, and scaling options.
Categories
- Artificial Intelligence (5)
- Best IT Training Institute Pune (9)
- Cloud (2)
- Data Analyst (55)
- Data Analyst Pro (15)
- data engineer (18)
- Data Science (104)
- Data Science Pro (20)
- Data Science Questions (6)
- Digital Marketing (4)
- Full Stack Development (7)
- Hiring News (41)
- HR (3)
- Jobs (3)
- News (1)
- Placements (2)
- SAM (4)
- Software Testing (70)
- Software Testing Pro (8)
- Uncategorized (33)
- Update (33)
Tags
- Artificial Intelligence (5)
- Best IT Training Institute Pune (9)
- Cloud (2)
- Data Analyst (55)
- Data Analyst Pro (15)
- data engineer (18)
- Data Science (104)
- Data Science Pro (20)
- Data Science Questions (6)
- Digital Marketing (4)
- Full Stack Development (7)
- Hiring News (41)
- HR (3)
- Jobs (3)
- News (1)
- Placements (2)
- SAM (4)
- Software Testing (70)
- Software Testing Pro (8)
- Uncategorized (33)
- Update (33)