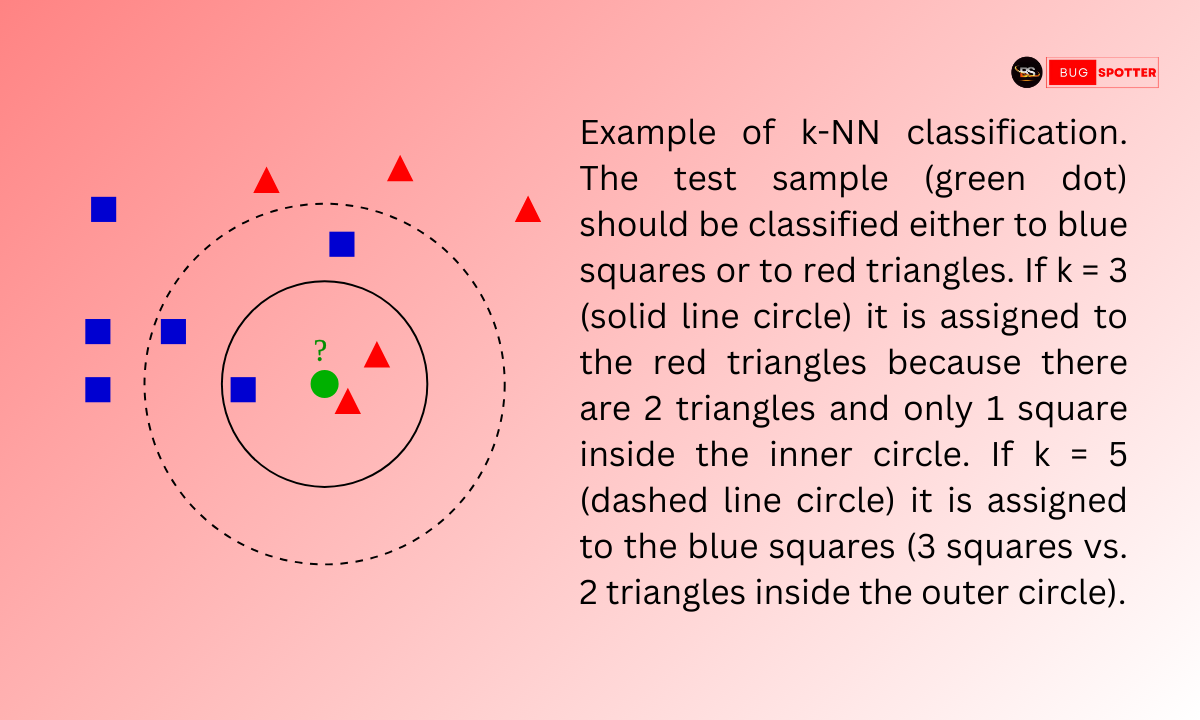
The K-Nearest Neighbors (KNN) algorithm is one of the simplest yet most powerful machine learning algorithms used for classification and regression tasks. It is a non-parametric, instance-based learning algorithm that makes predictions based on similarity measures. Due to its simplicity and effectiveness, KNN is widely used in various domains, from recommendation systems to fraud detection. In this guide, we will explore the fundamentals of KNN, its importance, practical applications, challenges, and best practices.
Understanding K-Nearest Neighbors (KNN) Algorithm
KNN is a lazy learning algorithm, meaning it does not construct a model during the training phase. Instead, it stores the training dataset and makes predictions by finding the closest data points (neighbors) to a given test instance.
How KNN Works:
Choose the number of neighbors (K): The choice of K determines how many nearest data points will be considered when making a prediction.
Calculate distances: Use distance metrics such as Euclidean, Manhattan, or Minkowski distance to measure the similarity between data points.
Identify the K nearest neighbors: Sort and select the top K closest neighbors.
Make a prediction:
For classification, use a majority vote among the K neighbors.
For regression, compute the average of the values of K neighbors.
Example of KNN in Action
Imagine you want to classify a new email as spam or not spam. KNN will:
Compare the email’s content with previously labeled spam and non-spam emails.
Identify the top K most similar emails.
Assign the most common label among the neighbors to the new email.
Why is KNN Important?
KNN is important due to its simplicity, adaptability, and versatility in handling various machine learning problems. Some key benefits include:
Ease of implementation: No need for complex mathematical computations.
Non-parametric nature: No assumptions about data distribution.
Effective for small datasets: Works well when computational efficiency is not a constraint.
Useful for multi-class classification: Handles multiple class labels effortlessly
Practical Applications of KNN
1. Healthcare – Disease Prediction
KNN is used in medical diagnosis, such as predicting diseases based on symptoms and past patient data.
2. Finance – Fraud Detection
Banks use KNN to detect fraudulent transactions by analyzing past transaction patterns.
3. Recommendation Systems
Streaming services like Netflix and Spotify use KNN to recommend content based on user preferences.
4. Image Recognition
KNN is applied in optical character recognition (OCR) to classify handwritten characters.
Common Challenges & Solutions in KNN
1. Computational Complexity
Challenge: KNN requires storing and scanning the entire dataset, which can be slow for large datasets.
Solution: Use KD-Trees or Ball Trees to optimize nearest neighbor searches.
2. Choosing the Right Value of K
Challenge: A very small K can lead to overfitting, while a large K can cause underfitting.
Solution: Use cross-validation to determine the optimal K value.
3. Handling High-Dimensional Data
Challenge: As the number of features increases, distance calculations become less meaningful.
Solution: Apply dimensionality reduction techniques like PCA to improve performance.
KNN vs. Other Machine Learning Algorithms
Feature
KNN
Decision Tree
SVM
Naive Bayes
Learning Type
Instance-Based
Tree-Based
Kernel-Based
Probabilistic
Model Complexity
Simple
Medium
Complex
Simple
Performance on Large Datasets
Slow
Faster
Faster
Fast
Interpretability
High
High
Medium
High
Training Time
Minimal
Moderate
High
Minimal
Memory Requirement
High
Medium
High
Low
Common Challenges & Solutions
Challenge
Solution
High computational cost
Use KD-Trees or Ball Trees for faster search.
Sensitive to irrelevant features
Feature selection and dimensionality reduction techniques.
Requires optimal K value selection
Use cross-validation to determine the best K.
Imbalanced data impact
Use weighted KNN or oversampling techniques.
Best Practices & Expert Insights
Feature Scaling: Normalize data using Min-Max scaling or Standardization to improve distance calculations.
Handling Imbalanced Data: Use weighted KNN where closer neighbors have more influence.
Dimensionality Reduction: Apply Principal Component Analysis (PCA) to remove irrelevant features and reduce computation time.
Optimize K Selection: Experiment with different values of K using grid search or cross-validation.
Use Efficient Search Algorithms: Implement KD-Trees or Approximate Nearest Neighbors (ANN) to speed up computations.